Транзитивность (коэффициент кластеризации) - один из важнейших показателей сетевого анализа.
Формула коэффициента кластеризации
2023-05-15
И как ее эффективно использовать
Транзитивность (коэффициент кластеризации) - один из важнейших показателей сетевого анализа.
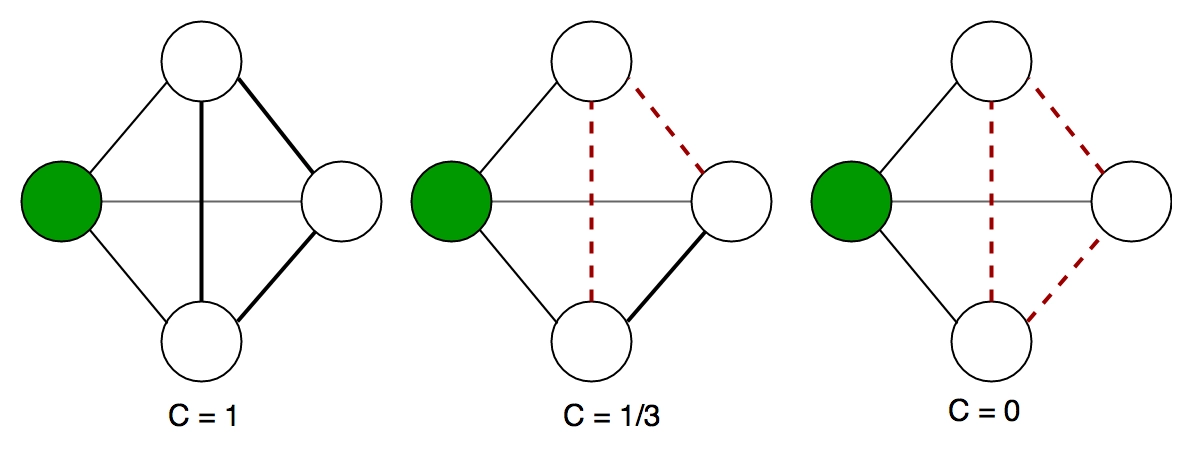
Транзитивность (коэффициент кластеризации) - один из важнейших показателей сетевого анализа. Этот коэффициент рассчитывается как отношение числа замкнутых троек ко всем возможным (замкнутым и открытым) тройкам. Напомним, что замкнутая тройка - это случай, когда между тремя вершинами присутствуют все возможные связи.
В теории графов коэффициент кластеризации - это мера степени, в которой узлы графа склонны объединяться в кластеры. В большинстве реальных сетей, особенно в социальных, есть доказательства того, что узлы склонны образовывать тесно связанные группы, характеризующиеся относительно высокой плотностью связей. Эта вероятность, как правило, выше, чем средняя вероятность случайного установления связи между двумя узлами.
Случайное удаление узлов почти не изменяет среднее расстояние между двумя узлами в зависимости от количества удаленных (высокая гибкость при атаке на сеть с распределением по степенному закону). Однако преднамеренное удаление узла с наибольшим числом связей разрушит сеть. Поэтому можно сказать, что веб-пространство - это сеть с высокой устойчивостью к случайному удалению узлов в сети, но уязвимая к преднамеренным атакам на них с высокой степенью связности с другими узлами.
Показатель кластеризации узла - это шанс того, что пара ближайших друг к другу объектов являются максимальными соседями. Чтобы объяснить подобную особенность, существует специализированная формула коэффициента кластеризации, которая применяется во время обработки массивов.
Для узла i, Ci = Ei/, где Ei - фактическое количество связей, ki - степень узла, а знаменатель - сумма потенциальных связей между ближайшими соседями узла i (если сеть или ее часть является полным графом).
Коэффициенты кластеризации могут быть усреднены по любой части или по всей сети и являются интегральным свойством: C = 1/n ΣCi.
Средний коэффициент кластеризации для группы участников школьной сети. Если можно выделить группы участников по какому-либо принципу, то реально определить коэффициент кластеризации внутри этой группы. Для членов устойчивых групп (клики) = 1.
Компьютеры могут представлять и анализировать происходящее. Примерами являются тексты, которые можно читать из книг, или изображения, которые можно передавать по сети.
Компьютеры могут понимать только числа. Поэтому любые данные должны быть представлены в цифровом виде, т.е. оцифрованы. Давайте объясним это на примере книги. Предположим, вы фотографируете страницу с помощью цифровой камеры. Сенсор этой камеры состоит из множества маленьких датчиков. Каждый датчик определяет цвет, который он видит, и представляет его в цифровом виде.
Поскольку k-means не может видеть кластеры, как мы, он измеряет качество путем нахождения среднего отклонения внутри каждого кластера. Основная идея k-means заключается в том, чтобы определить кластеры таким образом, чтобы минимизировать отклонение внутри каждого из них. Для оценки отклонения рассчитываются такие величины, как WCSS (сумма квадратов внутри кластера), т.е. сумма квадратов внутрикластерных расстояний от центра кластера. Эту особенность необходимо учитывать во время автоматизированной проверки и подсчета кластеров согласно специализированной формуле.
Коэффициенты глобальной кластеризации основаны на тройках узлов. Тройка состоит из взаимосвязанных узлов. Таким образом, треугольник содержит три замкнутых тройки с центром в каждом узле. Это означает, что три тройки треугольника получены из перекрывающихся экземпляров узлов. Глобальные кластеры - это количество замкнутых треугольников по сравнению с общим количеством треугольников. Первая попытка измерить этот показатель была предпринята Люсом и Перри. Эта мера дает представление о кластеризации в глобальных сетях и может быть применена как к неориентированным, так и к направленным сетям.
Технически процедура выполняется в два этапа. Сначала рассчитываются стандартизированные z-значения, которые затем умножаются на весовые коэффициенты. Например, вес самой важной переменной равен 0,5, вес следующей по важности кластерной переменной меньше, например, 0,3, а вес следующей по важности переменной еще меньше, например, 0,2. Если процедура взвешивания объективно необходима в ходе анализа, целесообразно применять два разных этапа: первый расчет выполняется на невзвешенных нормализованных переменных, а второй - на взвешенных нормализованных переменных. Важно учитывать обе переменные во время обработки массивов, независимо от коэффициента кластеризации.
В кластерах коэффициент силуэта - это величина, позволяющая оценить степень согласованности структуры кластера с обучающими данными, то есть качество кластеризации. Другими словами, коэффициент силуэта показывает, насколько каждый объект "похож" на другие объекты в кластере, к которому он отнесен при кластеризации, и насколько он "непохож" на объекты в других кластерах. Этот метод был предложен в 1987 году бельгийским статистиком Питером Руссо.
Идея метода заключается в вычислении коэффициентов, называемых кластерными силуэтами, которые присваиваются каждому объекту в кластере. Коэффициенты варьируются от -1 до 1. Значение, близкое к 1, означает, что объект похож на другие объекты в кластере и не похож на объекты в других кластерах. Если большинство объектов имеют значения коэффициентов, близкие к 1, то кластерная структура хорошо представлена и количество кластеров соответствует естественной группировке данных.
Таким образом, представлена лишь самая общая формулировка задачи анализа, решаемой индексным методом. Действительно, этот способ является одним из самых мощных инструментов экономического анализа во всех аспектах, начиная от анализа отдельных бизнес-единиц и заканчивая макроэкономическими исследованиями национальных экономик.
Изменение структуры какого-либо явления подразумевает изменение доли отдельной группы единиц в совокупности. Например, средняя заработная плата на предприятии может увеличиться в результате роста зарплаты сотрудников или повышения доли более высокооплачиваемых работников. На изменение среднего значения индекса влияют два фактора, и необходимо определить, в какой степени каждый из них влияет на общее движение среднего значения.
Значение индекса ясности близко к 1, а значение индекса отличительности к 0. Это указывает на то, что разделение на кластеры является четким. Значение индекса энтропии близко к нулю, а индексы компактности и изолированности близки к единице. Это указывает на то, что найденные кластеры компактны и достаточно разделимы. Высокое значение индекса эффективности указывает на то, что существует оптимальное количество кластеров. Другими словами, согласно значениям формальных критериев, качество вариантов кластеризации хорошее и, следовательно, нет объективных причин отвергать варианты, полученные по формальным критериям. Полученные результаты показывают, что формальный метод, использующий только метрическую меру сходства объектов, не может определить реальное разделение множества объектов на кластеры. Для этого необходима дополнительная информация. Источником этой информации является эксперт, который знает, что данные содержат сведения о трех видах ирисов и что versicolor является гибридом setosa и virgnica.
Кластерный анализ - это набор различных алгоритмов, используемых для отнесения объектов к кластерам. Известно большое количество алгоритмов.
В частности, выбор расстояния и меры сходства между объектами является сложной задачей. Кластерный анализ вводит понятие метрики для измерения сходства. Сходство или различие между объектами определяется метрическим расстоянием между ними. Если каждый объект описывается K признаками, которые могут быть представлены как точки в A-мерном пространстве, то его сходство с другими объектами будет определяться как соответствующее расстояние.
Выбор расстояния (p) является основным моментом, определяющим окончательный вариант разбиения. Наиболее распространенными являются принцип ближайшего соседа или принцип самого дальнего. В первом случае расстояние между множествами - это расстояние между самыми близкими элементами этих множеств; во втором случае - это расстояние между наиболее удаленными друг от друга элементами.
Евклидовы расстояния и расстояния Хемминга часто используются в задачах кластерного анализа.
Аккаунты имеют древовидную структуру, где "корнем" является сам аккаунт, а "листьями" - ключевые фразы. Ключевые фразы имеют определенную связь с объявлениями, которые они генерируют. Объявления объединяются в группы, которые, в свою очередь, объединяются в рекламные кампании. Если необходимо оценить коэффициент конверсии для данного ключевого слова, статистика, необходимая для определения значения оцениваемого параметра, собирается путем объединения ключевого слова с объявлением, группой, к которой принадлежит ключевое слово, и кампанией, к которой принадлежит группа объявлений. Схематически это соответствует "спуску по дереву" от "листьев" к "корням".
Кластеризация по методу K-means - это метод отнесения каждого наблюдения в наборе данных к одному из K кластеров.
Конечная цель - получить K кластеров, в которых наблюдения в каждом кластере очень похожи друг на друга, а наблюдения в разных отличаются.
Этот процесс продолжается до тех пор, пока не будут пройдены все возможные комбинации пар удаленных точек и не будут уточнены границы кластеров. Стабильность центров определяется путем сравнения абсолютного значения изменения среднего Евклидова расстояния между наблюдениями и соответствующими центрами с пороговым значением.
Коэффициенты локализации могут быть рассчитаны на основе использования различных данных, характеризующих деятельность предприятий - по объему производства, основным производственным фондам, численности персонала, производительности труда, инвестициям в основной капитал, инвестициям за рубежом, экспорту и импорту. Например, коэффициент локализации производства определяется отношением объема выпуска продукции основных предприятий региона к общему объему производства региона к аналогичному показателю по стране в целом.



Нажимая кнопку «Войти», Вы принимаете условия
Политики конфиденциальности



Задача кластеризации

Классификация и кластеризация: отличия

Что такое кластер?
Сбор семантического ядра

Обозначение в поисковых системах

Что такое семантический поиск, и как с ним работать

Поиск ключевых слов онлайн

Как правильно подобрать ключевые слова для сайта

Структура поисковых систем
Что такое кластер?
Классификация и кластеризация: отличия
Key collector кластеризации запросов
а вот здесь шеф жжет с задачками(((((((
Пожалуйста, не закрывайте страницу