Кластеризация данных является мощным инструментом для анализа и организации больших объемов информации. В нашей статье мы исследуем концепцию кластеризации и ее различные методы.
Кластеризация и ее методы
2023-05-22
И как ее эффективно использовать

Кластеризация данных является мощным инструментом для анализа и организации больших объемов информации. В нашей статье мы исследуем концепцию кластеризации и ее различные методы.
Кластеризация – группировка большого массива данных в кластеры для ускорения и упрощения исследования. Объекты разделяются на группы на основании схожих параметров, при этом разница между двумя типами должна быть значительной. Так, например, разделение товаров в супермаркете на «мясо», «бытовую химию», бакалею и т.д. является простейшим примером кластеризации. Разница разбивки и классификации заключается в том, что при разбивке нет заданного списка групп. Он определяется в процессе проведения анализа.
Использование методов кластеризаций может быть представлено в поэтапном виде.
После проведенных вычислений и получения результатов анализа существует возможность коррекции метрики и способов кластеризаций для получения более достоверных данных.
Как выявляется схожесть объектов? Прежде всего необходимо выстроить векторы расстояний для объектов в выборке. Чаще всего их приводят к числовым значениям. Некоторые алгоритмы предназначены для анализа не количественных, а качественных параметров.
После определения вектором параметров, можно приступать к нормализации. Она необходима для того, чтобы компоненты вносили одинаковый вклад при проведении вычислений. Нормализация подразумевает сведение всех значений к определенному диапазону, например,.
Между парами объектов вычисляется «расстояние» (этим словом характеризуется степень схожести). Среди существующих метрик можно отметить:
|
1. Евклидово расстояние |
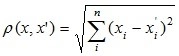 |
|
2. Квадрат евклидова расстояния |
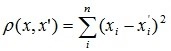 |
|
3. Расстояние городских кварталов |
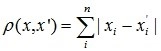 |
|
4. Расстояние Чебышева |
|
|
5. Степенное расстояние |
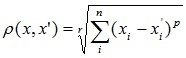 |
К способам кластеризации чаще обращаются, когда возникает необходимость выполнить классификацию, но собрать при этом обучающую выборку не представляется возможным. Для проведения оценки разбивки используется сбор валидационной выборки с меньшим количеством примеров.
Стоит учесть, что точность результатов supervised-методов является более высокой, поэтому при сборе обучающей выборки на первом плане стоят именно задачи классификации.
В качестве хорошего примера применения кластеризаций можно использовать семантический анализ географических данных. В мобильных сервисах, которые собирают данные о местоположении клиентов, зачастую нужно определять, где бывал пользователь. GPS-координаты не всегда точны. Помимо погрешностей системы пользователь также постоянно находится в движении, поэтому нельзя говорить о точных данных, вместо них имеется лишь скопление точек, расположенных хаотично.
Решение задач становится сложнее, когда по полученным данным мы попытаемся определить поведение тысяч пользователей в каком-либо месте. Например, есть задача выяснить, в каких локациях у здания аэропорта пользователи чаще садятся в такси. С первого взгляда может показаться, что достаточно лишь взглянуть на полученные данные и можно выделить необходимые группы кластеризаций.
Однако на деле ситуация может быть сложнее, ведь данные GPS -системы не точны и, если верить им, то такси забирает людей и внутри здания, и со взлетно-посадочной полосы.

Над решением данной задачи работали при создании пикап-пойнтов (оптимальных точек вызова автомобиля, которые отображаются в приложении) в одном сервисе такси. Расположенные на карте точки кластеризировались так, чтобы кластер совпадал с определенным местом. В качестве центров, которые удовлетворяют потребностям разбивки, использовались отображаемые в сервисе пикап-пойнты.
Также к наглядному примеру кластеризации географических данных можно отнести приложения просмотра фото в мобильном устройстве. С его помощью можно просмотреть геометки, в которых были сделаны фотографии. Однако по мере отдаления карты можно увидеть разное число кластеров.
В качестве примера, конечно, могут выступать не только анализы геоданных, но это наиболее понятные методы кластеризаций. Если также представить, что мы работаем с большим количеством точек, и нам нужно разработать пикап-пойнты для сервиса такси. Классификация методов разбивки позволяет подобрать наиболее оптимальный вариант, который можно использовать в анализе.
Можно попробовать идти от простого и логичного, для этого необходимо объединить точки, расположенные друг от друга в двух-трех метрах, после отобрать популярные места.
Чтобы выполнить задачу, нужно простроить граф на основании точек, данные о которых имеются: точки, расстояние между которыми не превышает трех метров, следует объединить ребрами. Компоненты связности в данном графе – это кластеры.
Методика расчета имеет свои недостатки. Так, можно на выходе получить цепочку большой длины, в которой попарное расстояние между целым рядом точек будет не превышать 3 метра. Эта цепь также относится к одной компоненте связности. В результате отсечка по трем метрам относится к диаметрам кластера косвенно, а кластеры в свою очередь будут иметь слишком большие размеры. Помимо этого недостатка имеется и другой: выбор расстояния отсечки нелогичен. Если важно не только само решение поставленной задачи, но и разработка общего способа разбивки, то нужно определиться с конкретными значениями метода.
Данный метод предполагает не строить ребра в графе, а удалять их. Для этого надо начать строить минимальное остовное дерево, при этом необходимо рассчитывать промежуток между точками веса ребер. В таком случае, удалив N ребер с максимальным весом, в результате получаем N+1 компоненту связности. По аналогии с предыдущими методами расчета, принимаем ее за кластер.
Отличие двух способов заключается в том, что главным является не промежуток, на котором строится ребро, а число кластеров. Если основной целью расчета числится настройка пикап-пойнтов на определенном участке (вокзал, ресторан, многоквартирный дом), то мы имеем представление, сколько пикап-пойнтов должно получиться в результате. Если не делить карту на локации, можно сформировать требуемое количество кластеров, чтобы можно было сделать выбор, при этом сравнительно малое, чтобы в конкретный кластер попадало представленное число точек. Схожая логика будет действовать и для решения других задач кластерного анализа: число кластеров – оптимальный параметр, его также можно настраивать вручную. Стоит отметить, что во многих методах количество кластеров является гиперпараметром.
В разбивке часто используется этот метод. Он основан на итеративном повторении двух действий.
Сначала подбирается K произвольных центров. Остальные объекты становятся частью кластера, центр которого находится на минимальном расстоянии. После этого происходит пересчет центров кластеров путем определения среднего арифметического векторов объектов, входящих в состав кластера. После того, как произошло обновление центров, объекты внутри кластеров вновь перераспределяются. Работа проводится до тех пор, пока центры кластеров не останутся без изменений после очередной итерации.

Сбор и группирование ключевых запросов начинается с определения трех основных характеристик.
Принципы группировки слов могут подбираться на основе одного из способов.
Этот вид группировки поисковых запросов разделяется еще на 3 способа: Soft, Moderate и Hard:

Различные исследования гласят, что хард разбивка показывает от 90% точности при установленном пороге в 3 УРЛа. Даже опытный оптимизатор в процессе ручной разбивки может демонстрировать точность около 70%, и это считается отличным результатом без использования дополнительных инструментов. Если же новичок должен будет объединить запросы вручную, его точность чаще всего не будет превышать 30%. При этом полнота данных хард оптимизации чаще всего не превышает 40%. Но при сравнении с ручной работой, максимум, на что можно рассчитывать – 20%.
Софт разбивка выдает более полные данные, однако их точность достаточно низкая. Для продвижения запросов требуется порог хотя бы в 5 URl, но при этом происходит снижение полноты до 23%.
Несмотря на то, что Soft по результатам исследований показывает неутешительные данные, ее стоит применять в случаях, когда проводится трафиковая раскрутка ресурса и преследуется цель привлечения наибольшего количества запросов. Hard подходит для поиска и использования на странице конкретного перечня запросов.
Плюсы:
Минусы:



Нажимая кнопку «Войти», Вы принимаете условия
Политики конфиденциальности



Задача кластеризации

Классификация и кластеризация: отличия

Что такое кластер?
Сбор семантического ядра

Яндекс Вордстат – руководство по использованию

Оптимизация сайта на Тильде

Поиск ключевых слов онлайн

Как правильно подобрать ключевые слова для сайта

Структура поисковых систем
Что такое кластер?
Классификация и кластеризация: отличия
Key collector кластеризации запросов
а вот здесь шеф жжет с задачками(((((((
Пожалуйста, не закрывайте страницу